Everyone seems to be building AI agents now. But ask ten developers what an AI agent actually is, and you'll get ten different answers. Some say it is any LLM with tool access. Others define it by the ability to autonomously take actions in the world. A few will point at an existing chatbot and call it an agent.
This definitional vagueness is not just an academic problem. It leads to a security problem. How can you protect a system you cannot describe precisely?
Looking for an AI Agent Definition
Beyond the generic definitions that emphasize the level of autonomy in making decisions, I'd like to point out a slightly more technical one that I prefer. It comes from Microsoft and seems to be quite consistent with the OWASP definition:
"An AI agent is a flexible software program that uses generative AI models to interpret inputs, [...] reason through problems, and decide on the most appropriate actions. [...] Agents are built on five core components:
- Generative AI model serves as the agent's reasoning engine. It processes instructions, integrates tool calls, and generates outputs, either as messages to other agents or as actionable results.
- Instructions define the scope, boundaries, and behavioral guidelines for the agent. Clear instructions prevent scope creep and ensure the agent adheres to business rules.*
- Retrieval provides the grounding data and context required for accurate responses. Access to relevant, high-quality data is critical for reducing hallucinations and ensuring relevance.
- Actions are the functions, APIs, or systems the agent uses to perform tasks. Tools transform the agent from a passive information retriever into an active participant in business processes.
- Memory stores conversation history and state. Memory ensures continuity across interactions, allowing the agent to handle multi-turn conversations and long-running tasks effectively."
Agents differ from traditional applications, which are based on fixed rules. By dynamically orchestrating workflows according to real-time context, agents gain adaptability that allows them to manage ambiguity and complexity beyond the capability of traditional software.
We can visualize this definition into the following diagram:
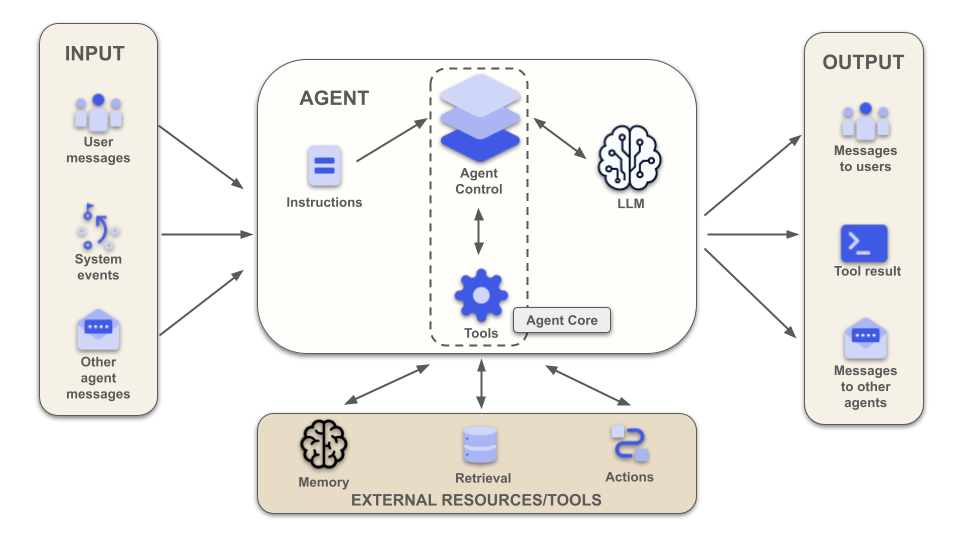
Aside from input, output, and external resources, the heart of an AI agent is a collection of instructions, the LLM, and the Agent Core.
The LLM is, as we know, the brain of the agent, the component that performs the necessary reasoning and makes decisions. The Agent Core is the software component that orchestrates the interactions between the LLM and the rest of the world. The Agent Core is the code in your Python, JavaScript, C#, etc. application that interacts with the LLM.
Within the Agent Core, I highlighted two components: the Agent Control and the Tools. The Agent Control is the heart of the agent, the part that coordinates all the interactions between the LLM and the external world. The Tools component represents all the functionality made available to the LLM, such as calculation functions, file system access, etc. This component is also the interface to external tools and resources. The combination of the Agent Control and the Tools components builds the Agent Core: just plain old-style code, with no intelligent functionality.
Looking at the diagram, we notice two interesting things:
- The two true components of an AI agent are the Agent Core, which is deterministic, and the LLM, which is not deterministic.
- The Agent Core is the only component that interacts with the LLM.
These two simple observations are fundamental to understanding the nature of an AI agent and how we can secure it.
The Two Souls of an AI Agent
The first observation highlights that the two core components of an AI agent are a traditional deterministic application and an LLM, which is not deterministic.
The Agent Core sends the input to the LLM, provides functionalities to it, processes the output, etc. by running deterministic code. You can analyze it, test it, you know how it works and you know that for a given input you will always get the same output.
The LLM model has a different nature: it is not deterministic. Given the same input on two different occasions, a generative AI model may produce different outputs. It can reason in unexpected directions, interpret ambiguous instructions in ways you did not anticipate, and combine information from its context in ways that surprise even the people who built it. This is at the same time the power and the problem with LLMs.
Saying that LLMs are not deterministic is not the same as saying it is non-deterministic. While commonly LLMs are considered to be non-deterministic, this is not correct in computational terms. See this article to learn why LLMs are not non-deterministic.
So, in the architecture of an AI agent, we can identify what I call two souls: a deterministic soul (the Agent Core) and a probabilistic soul (the LLM).
If you are a philosophy enthusiast, you might notice a certain reference to the dualities of the human soul: from Plato's myth of the winged chariot to St. Augustine's two wills to Nietzsche's distinction between the Apollonian and Dionysian concepts.
The tension is the same: one controlled, one wild. And the wild one gets all the attention.
Traditional software security is built almost entirely on the assumption of determinism. You know what inputs are valid, you know what outputs to expect, and you can test edge cases exhaustively. AI agents shatter this assumption. The probabilistic soul introduces a category of behavior that no test suite can fully cover.
The implication for security follows directly: you cannot secure the model itself. What you can do is architect the deterministic soul to constrain what the probabilistic soul can reach.
The Three Laws of AI Security Applied
Some time ago, I wrote an article about the three laws of AI security. Paraphrasing Asimov's three laws of robotics, I defined similar laws to control the less deterministic part of AI. Similar to what I have analyzed in this article, I observed that the fundamental problem in building secure AI-powered applications is the loss of that control we have become accustomed to with deterministic software.
Based on the discussion we have had so far, we say that in the architecture of an AI agent there is a component that makes decisions and is not deterministic (LLM) and one that executes orders in a deterministic way (Agent Core).
Paradoxically, the decision-making part is beyond our control: it is not deterministic, we have no tools to predict with certainty whether it will make the decision we expect or not.
But in this scenario we forget one important thing: it is not only the LLM that makes decisions. The Agent Core can make decisions as well. And that is not all. Our earlier second observation tells us that the Agent Core is the only component that interacts with the LLM. All the input coming from the user, other agents, external tools, and resources is filtered by the Agent Core before going to the LLM. All the output going to the users, other agents, external tools and resources comes through the Agent Core. The LLM cannot directly interact with the external world. That is a great thing in terms of security!
Let’s see how to apply each law to the soul-based architecture of an AI agent.
The Data Control Law
The first law is about gaining control over data. It states:
An AI agent must safeguard all data entrusted to it and shall not, through action or inaction, allow this data to be exposed to any unauthorized user.
Translating this law in terms of the AI agent architecture, we can say that, when acting on behalf of a user, the probabilistic soul must never access data that the user is not authorized to access.
To implement this law, make sure your Agent Core has control over any data going to the LLM and to the user/other agents. Make sure that private data remains private. Filter data before sending it to the LLM, the user, or other agents. Apply access control according to your use case.
A typical example of the need for data control is in retrieval algorithms implementation, such as in RAG systems. You specialize your agent’s knowledge with an external source of data, such as a vector database, and want to prevent the user from accessing data they are not authorized to.
The deterministic soul of the agent has the responsibility to filter the data before passing it to the LLM. Without this filter, a user asking “summarize my documents” could inadvertently receive documents belonging to other users: a data leak the LLM itself would never catch.
Take a look at the following blog posts to see how to implement the data control law for RAG systems:
- Building a Secure RAG with Python, LangChain, and OpenFGA
- Secure Java AI Agents: Authorization for RAG Using LangChain4j and Auth0 FGA
- Secure a .NET RAG System with Auth0 FGA
- Build a Secure RAG Agent Using LlamaIndex and Auth0 FGA on Node.js
The Command Control Law
The second law focuses on controlling the command flow and making sure that an AI agent does what it is called to do. Nothing more. The law says:
An AI agent must execute its functions within the narrowest scope of authority necessary. It shall not escalate its own privileges, share secrets, or obey any order that would conflict with the First Law.
Let’s translate this law in terms of the agent architecture.
If you want to prevent an agent from sharing secrets, do not share secrets with the agent. Or better, the probabilistic soul (LLM) must never access secrets or tokens. The deterministic soul can manage tokens, but you must take steps to minimize the likelihood of these falling into the wrong hands. For example, you should use tokens with a short life, but this requires frequent renewals with refresh tokens. If your agent interacts with multiple third-party services (e.g., Gmail, Slack, Stripe, etc.), do not store long-lived tokens locally for each third-party service. Use a token vault instead.
Check out these articles to learn what is the best approach to protect the tokens used by your agent:
- Build an AI Assistant with LangGraph, Next.js, and Auth0 Connected Accounts
- Secure Third-Party Tool Calling in LlamaIndex Using Auth0
- MS Agent Framework and Python: Use the Auth0 Token Vault to Call Third-Party APIs
To give your agent only the permissions it needs, use scopes in your access tokens and apply the principle of least privilege.
But threats to the second law do not just come from token and permission management. These can arise from the input received by the agent: consider prompt injection, which could fool the probabilistic soul of your agent and bypass certain constraints.
The output generated by the LLM can also pose a threat, especially when it is intended to invoke a tool.
In other words, the deterministic soul is responsible for sanitizing LLM’s input and output. To learn some techniques for preventing prompt injections and handling improper output, read the following articles:
- Hiding Prompts in Plain Sight: A New AI Security Risk
- Trusting AI Output? Why Improper Output Handling is the New XSS
The Decision Control Law
The third law is about decision control and says:
An AI agent must cede final authority for any critical or irreversible decision to its human operator, as long as this deference does not conflict with the First or Second Law.
In traditional software, the paths between a given input and its output are somehow predetermined. In an agent, you have an unlimited variety of combinations between inputs and outputs, determined almost entirely by the decisions made by the LLM in interpreting the prompt.
In the AI agent architecture, we are delegating to the probabilistic soul the task of interpreting the input and determining what tools to use to achieve a given goal. This gives the agent enormous flexibility and, at the same time, a great responsibility.
To implement the decision control law, you should limit the responsibility of your agent by identifying what are the most critical actions that it can do on your behalf and ask confirmation for executing those actions. The deterministic soul is responsible for involving the user in critical decisions.
Depending on the type of agent you are building, these confirmation requests can be interactive or asynchronous. Think of interactive requests like those made by Claude Code or GitHub Copilot when they ask for permission to write to a folder or modify your code. Asynchronous permission requests are those that an unattended agent can send you via email or push notifications.
Whatever your case, engaging the user is crucial to preventing potentially irreparable damage.
Here are a few examples of how you can deal with asynchronous authorization using Auth0:
- Securing AI Agents: Mitigate Excessive Agency with Zero Trust Security
- Secure “Human in the Loop” Interactions for AI Agents
- Implementing Asynchronous Human-in-the-Loop Authorization in Python with LangGraph and Auth0
- Use CIBA Authentication with Auth0 and .NET
Your Takeaways for Securing AI Agents
The “two souls” model gives you a concrete mental model for AI agent security. The security insight here is counterintuitive: the component you control least (the LLM) is not where you focus your security effort. Security must focus on architecting the deterministic soul to constrain the probabilistic one. This perspective allows you to apply the Three Laws of AI Security by enforcing the Agent Core's responsibility for filtering data, sanitizing inputs/outputs, and managing critical human-in-the-loop decisions.
Here are the main takeaways that I want to highlight:
- Security is in the code: You cannot secure the LLM directly; secure the deterministic Agent Core that wraps and controls it.
- Constraint is control: Use the Agent Core to strictly enforce boundaries on the LLM's access to data, secrets, tokens, and external actions.
- Human override: Implement "Human in the Loop" protocols in the deterministic soul for all critical or irreversible decisions.
Implementing all of this from scratch can be challenging and risky. Auth0 for AI Agents helps you handle the deterministic security layer for you (token management, access control, and human-in-the-loop flows) so you can focus on what your agent actually does.
About the author

Andrea Chiarelli
Principal Developer Advocate
I have over 20 years of experience as a software engineer and technical author. Throughout my career, I've used several programming languages and technologies for the projects I was involved in, ranging from C# to JavaScript, ASP.NET to Node.js, Angular to React, SOAP to REST APIs, etc.
In the last few years, I've been focusing on simplifying the developer experience with Identity and related topics, especially in the .NET ecosystem.